Graph Databases
Document DBs are
known to be very good at searching data among billions or trillions of records, with little or no performance
degradation. At the same time, they have one big limitation: they do not play
well with too many relationships between entities.
Databases are an
essential part of most IT systems, as they are the containers of the most
valuable “piece of the puzzle”: the Data.
Relational Databases
(RDBMS) have been playing a major
role in the Data Architecture, being
a sort of standard in the software
industry; products such as Oracle, Microsoft Sql Server, MySql have been used for almost any
software or services worldwide for several years. Those are by now considered mature
technologies, tested and refined over the years to cope with constantly challenging
data requirements and new software paradigms coming up all the time.
However, since a few years, Social Media Networks systems such as Facebook, Twitter, LinkedIn (to name a few), introduced a
new concept that represent an incredible challenge to traditional Databases: Big Data.
“Big data is a broad
term for data sets so large or complex that traditional data processing
applications are inadequate.” [Wikipedia].
And:
“An example of big
data might be petabytes (1,024
terabytes) or exabytes (1,024
petabytes) of data consisting of billions
to trillions of records of millions of people—all from different sources
(e.g. Web, sales, customer contact center, social media, mobile data and so
on). The data is typically loosely structured data that is often incomplete and inaccessible.” [Webopedia]
This is why NoSql
Databases have emerged in the
software industry over the years, with some famous name such as MongoDB (you can read my previous
article on Geographically Distributed Replica Set withMongoDB and Azure), Cassandra,
RocksDB, RavenDB; these are just a few examples of Key-Value Stores (or Document
Databases), which can cope with Big
Data better than traditional RDBMS.
Other technologies such as Redis or Hadoop and MapReduce are also used worldwide to
store and view Big Data.
Document DBs are
known to be very good at searching data among billions or trillions of records, with little or no performance
degradation. At the same time, they have one big limitation: they do not play
well with too many relationships between entities.
This is where Graph Databases come into picture:
“In mathematics, and
more specifically in graph theory, a graph is a representation of a set of
objects where some pairs of objects are connected by links.” [Wikipedia]
Graphs
are currently the best way to represent data in Social Networks and other similar systems, where relationships
between people, their messages, posts, likes, comments, and all other types of
social media interactions, often in the big
numbers, are best represented with graphs.
A few products are on the market nowadays offering graph data storage, and among all Neo4j
seem to be the most mature product at the moment. This system has his own Query Language: Cypher, which similarly to SQL
allows to search the Database for
specific data, now with an optimized approach for the Shortest Path.
Neo4j stores data
into collections of Nodes (equivalent
of Tables in RDBMS) and Links (equivalent of Foreign Key Relations in RDBMS). The first main difference is
that Links are completely decoupled
from Nodes, and so they can be
created or deleted at any time, without any impact on the data (try to remove a
FK between two tables full of data
on a RDBMS…). This is ideal for
systems that are under constant evolution (such as, but not limited to Social Networks).
Another important concept of Neo4j is that Links are semantic: in the example of a private message conversation
between two users, each user can either Send
or Receive a message, hence having
two different types of relations to messages.
This semantic cannot be easily represented by a traditional RDBMS, and would require some coding to
represent it, while out-of-the-box
it’s easy to achieve it on a Graph
DB:
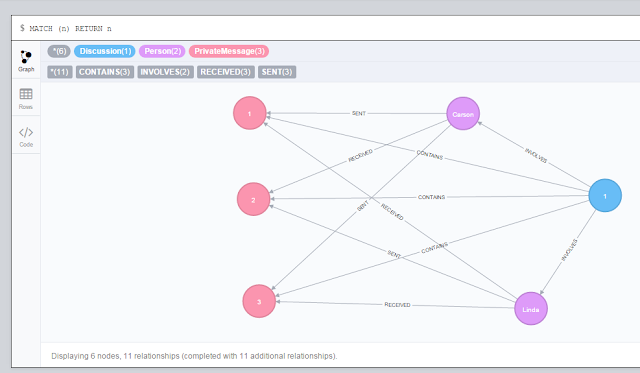

The image above shows the Neo4J User Interface (a local browser app using the Neo4j REST API), running a Cypher Query “MATCH (n) RETURN n”, which returns all Nodes and Links in the
system; the output is displayed as a Data
Graph, rendered by default as an SVG file, where you can easily layout
and re-arrange all Nodes and Links for the best displaying, but it
can also be displayed as tabular data, or the JSON plain response.
Here you can also notice the semantic Links, which also allow to easily representing the time concept within the conversation (Discussion in the graph):
- Person Carson sends Message 1 to Person Linda
- Person Linda receives Message 1 from Person Carson
- Person Linda sends Message 2 to Person Carson
- Person Carson receives Message 2 from Person Linda
- Person Carson sends Message 3 to Person Linda
- Person Linda receives message 3 from Person Carson
No extra code is needed to represent this logical sequence,
unlike with traditional RDBMS.
Just as a side-note, systems like Facebook and Twitter use
their own custom Graph solution,
built on top of MySql RDBMS; the
most plausiblereason is that they started with RDBMS
technology years ago when Graph DBs
did not exist yet, they invested lots of time, money and effort on it, and
slowly transitioned to a custom Graph
solution over time (see TAO and FlockDB).
And if you are wondering about performance numbers, a lot of benchmarking
tests [1] have been done already,
and it appears that Graph Databases
are indeed a strong technology, here to stay in the long run.
So, are Graph
Databases going to replace RDBMS altogether?
Not really.
RDBMS will still
be in place for a long time; however they won’t be anymore the only way to
store data in an Enterprise, as the IT industry is going toward a Polyglot Persistence, where
different data sources and technologies will be used individually to address
specific needs, and together to form the Enterprise
Big Data.
[1] Benchmarking Graph Databases:



Comments
Post a Comment